
In this blog post we’ll discuss how Cloudflare Workers enabled us to quickly improve the resiliency of a legacy system. In particular, we’ll discuss how we prevented the email notification systems within Cloudflare from outages caused by external vendors.
Email notification services
At Cloudflare, we send email notifications to customers such as billing invoices, password resets, OTP logins and certificate status updates. We rely on external Email Service Providers (ESPs) to deliver these emails to customers.
The following diagram shows how the system looks. Multiple services in our control plane dispatch emails through an external email vendor. They use HTTP Transmission APIs and also SMTP to send messages to the vendor. If dispatching an email fails, they are retried with exponential back-off mechanisms. Even when our ESP has outages, the retry mechanisms in place guarantee that we don’t lose any messages.
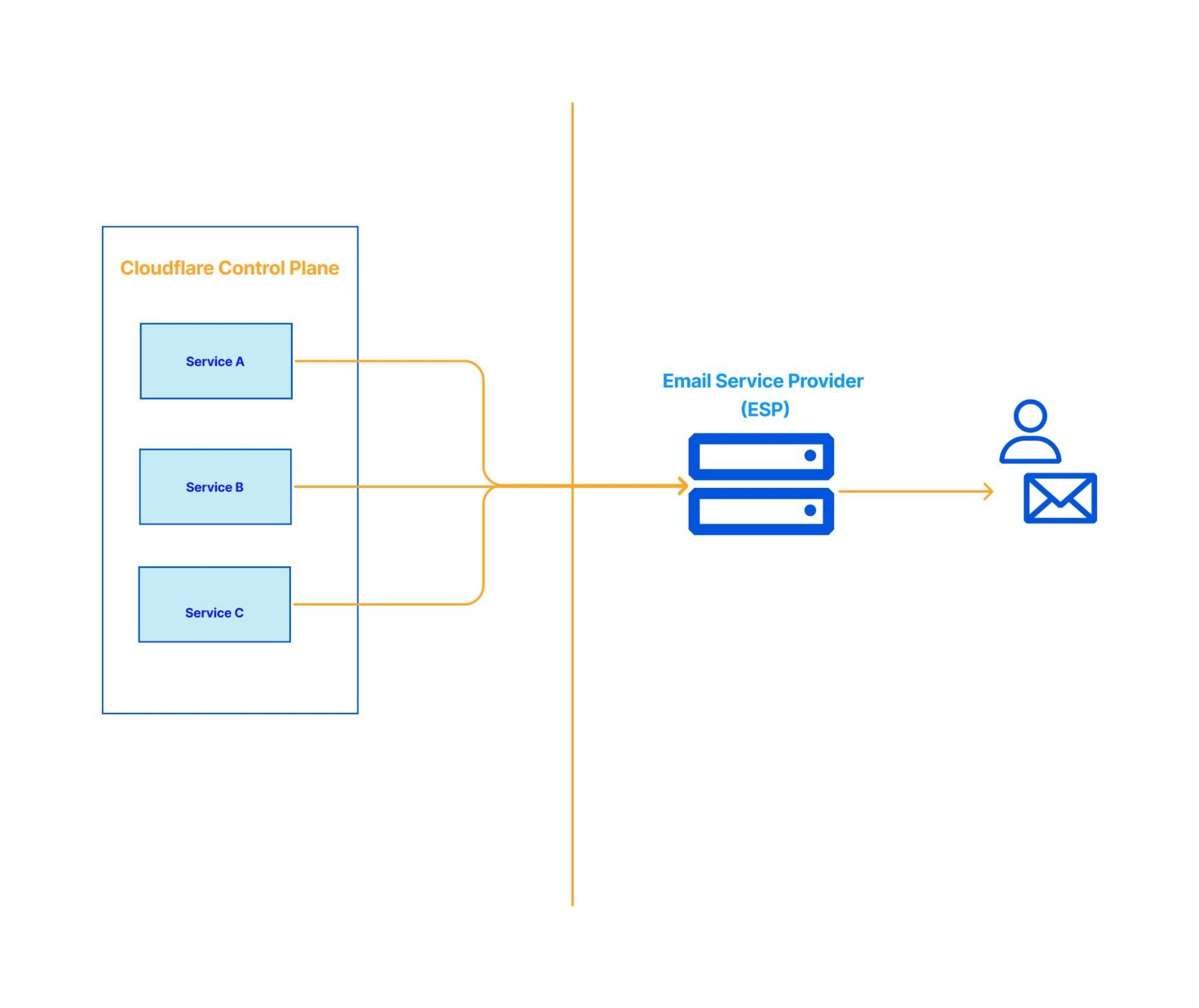
Why did we need to improve resilience?
In some cases, it isn’t sufficient to just deliver the email to the customer; it must be delivered on time. For example, OTP login emails are extremely time sensitive; their validity is short-lived such that a delay in sending them is as bad as not sending them at all. If the ESP is down, all emails including the critical ones will be delayed.
Some time ago our ESP suffered an outage; both the HTTP API and SMTP were unavailable and we couldn’t send emails to customers for a few hours. Several thousand emails couldn’t be delivered immediately and were queued. This led to a delay in clearing out the backlogged messages in the retry queue in addition to sending new messages.
Critical emails not being sent is a major incident for us. A major incident impacts our customers, our business, and also our reputation. We take serious measures to prevent it from happening again in the future. Hence improving the resiliency of this system was our top priority.
Our concrete action items to reduce the failure possibilities were to improve availability by onboarding another email vendor and, when ESP has an outage, mitigate downtime by failing over from one vendor to another.
We wanted to achieve the above as quickly as possible so that our customers are not impacted again.
Step 1 – Improve Availability
Introducing a new vendor gives us the option to failover. But before we introduced it we had to consider another key component of email deliverability, which is the email sender reputation. ISPs assign a sending score to any organization that sends emails. The higher the score, the higher the probability that the email sent by the organization reaches your inbox. Similarly the lower the score, the higher the probability it reaches your spam folder.
Adding a new vendor means emails will be delivered from a new IP address. Mailbox providers (such as Gmail or Hotmail) view new IP addresses as suspicious until they achieve a positive sending reputation. A positive sending reputation is determined by answering the question “did the recipient want this email?”. This is calculated differently for different mailbox providers, but the simplest measure would be that the recipient opened it, and perhaps clicked a link within. To build this reputation, it’s recommended to use an IP warm-up strategy. This usually involves increasing e-mail volume slowly over a matter of days and weeks.
Using this new vendor “only” during failovers would increase the probability of emails reaching our customer’s spam folder for the reasons outlined above. To avoid this and establish a positive sending reputation we want to send a constant stream of traffic between the two vendors.
Solution
We came up with a weighted traffic routing module, an algorithm to route emails to the ESPs based on the ratio of weights assigned to them. This is how the algorithm works roughly:

This algorithm solves the problem of maintaining a constant stream of traffic between the two vendors and to failover when outages happen.
Our next big question was “where” to implement this module? How should this be implemented so that we can build, deploy, and test as quickly as possible? Since there are multiple teams involved, how can we make it quicker for all of them? This leads to a perfect segue to our next step.
Step 2 – Mitigate downtime
Let’s discuss a few approaches on where to build this logic. Should this just be a library? Or should it be a service in itself? Or do we have an even better way?
Design 1 – A simple solution
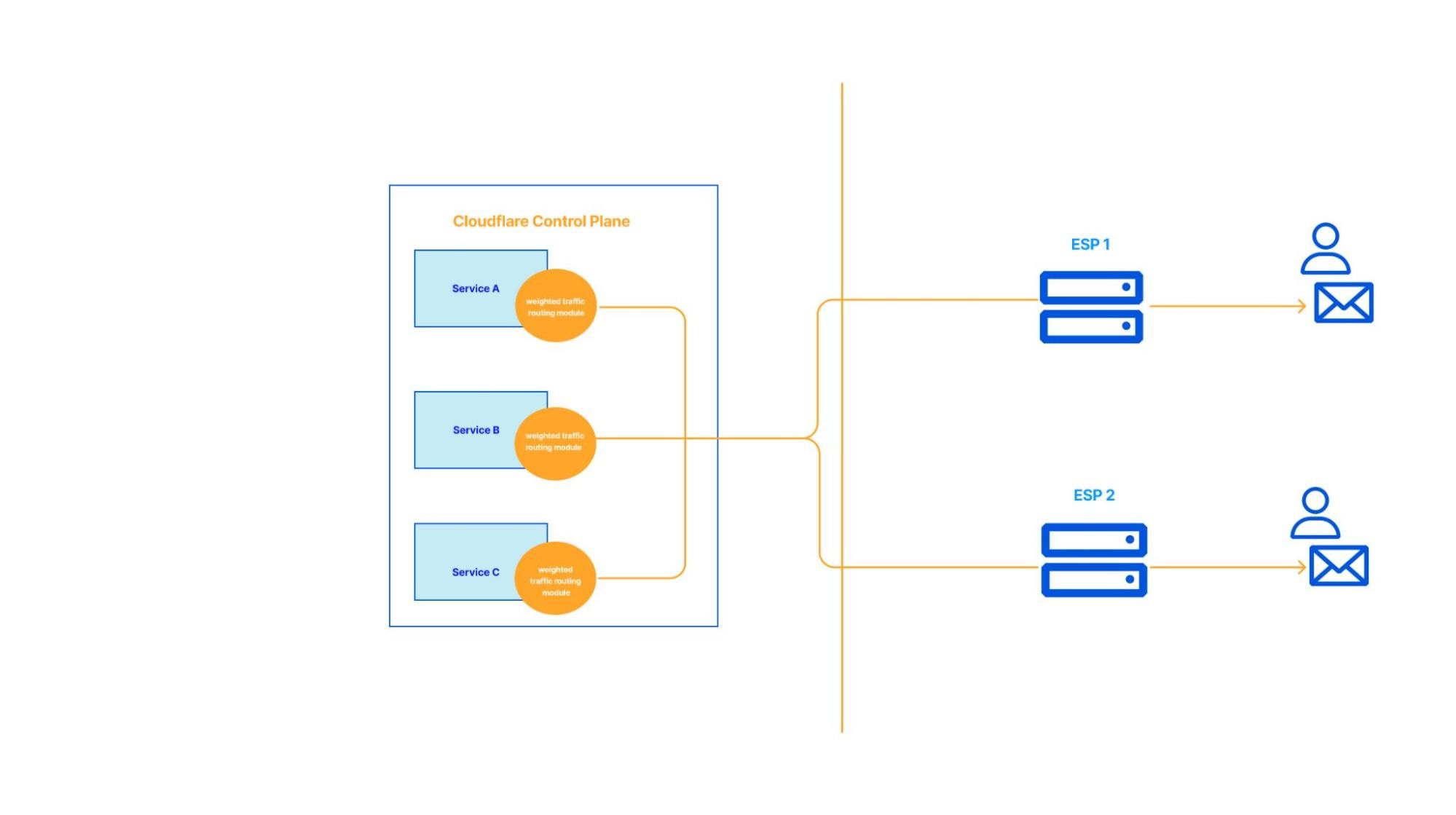
In this proposed solution, we would implement the weighted traffic routing module in a library and import it in every service. The pros of this approach is that there are no major changes to the overall existing architecture. However, it does come with quite a few drawbacks. Firstly, All of the services require a major code change and a considerable amount of development effort would have to be spent on this integration and testing end-to-end. Furthermore, updating libraries can be slow and there is no guarantee that teams would update in a timely manner. This means we may see teams still sending only to the old ESP during an incident, and we have not solved the problem we set out to.
Design 2 – Extract email routing decisions to its own microservice
The first approach is simple and doesn’t disrupt the architecture, but is not a sustainable solution in the long run. This naturally leads to our next design.
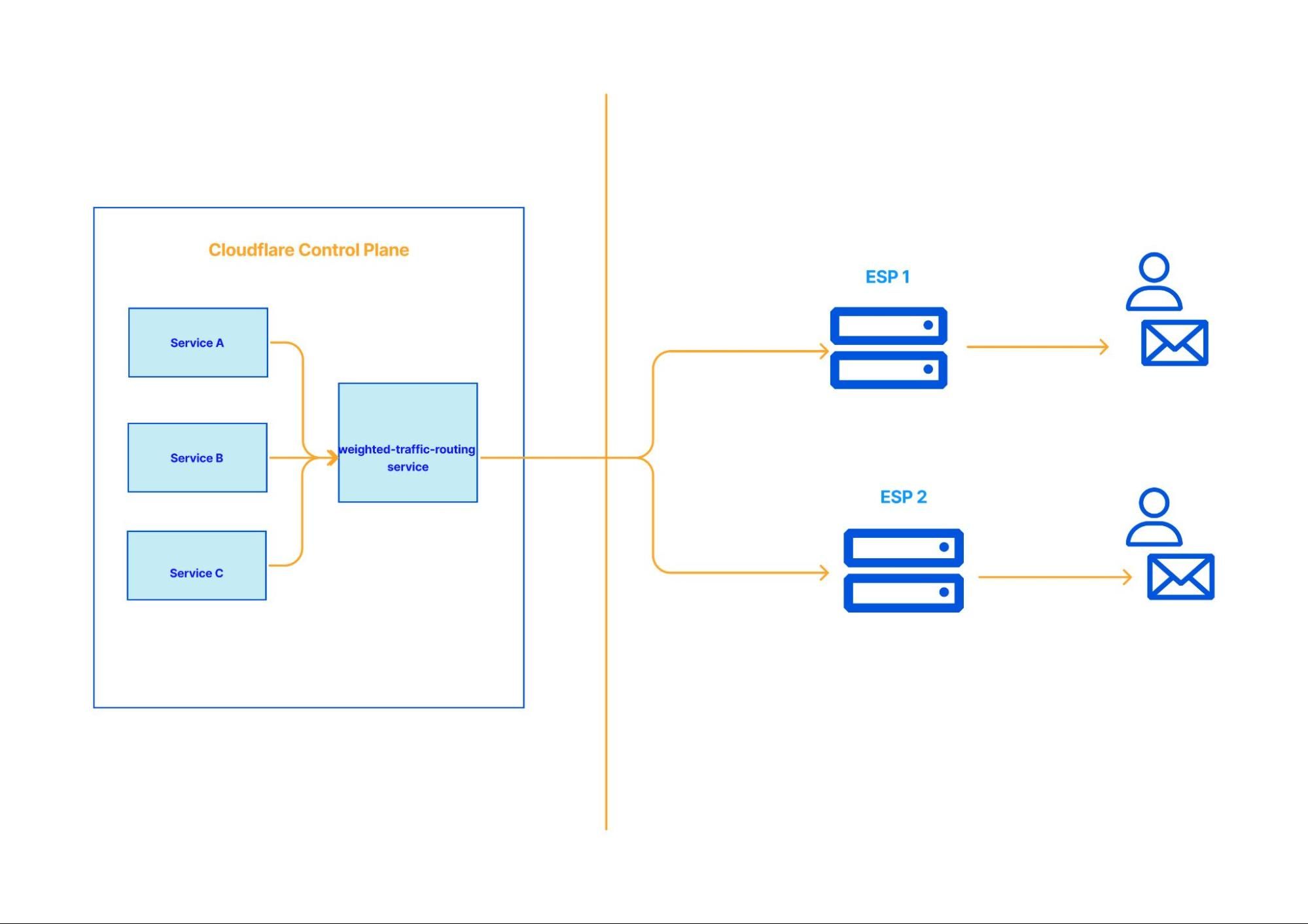
In this iteration, the weighted-traffic-routing module is extracted to its own service. This service decides where to route emails. Although it’s better than the previous approach, it is not without its drawbacks.
Firstly, the positives. This approach requires no major code changes in each service. As long as we honor the original ESP contract, team’s should simply need to update the base URL. Furthermore, we achieve the Single Responsibility Principle. When outages happen, the configurations have to be changed only in the weighted-traffic-routing service and this is the only service to be modified. Finally, we have much more control over retry semantics as they are implemented in a single place.
Some of the drawbacks of taking this approach are the time involved in spinning up a new service from scratch – building, testing, and shipping it is not insignificant. Secondly, we are adding an additional network hop; previously the email-notification-services talked directly to the email service providers, now we are proxying it through another service. Furthermore, since all the upstream requests are funneled through this service, it has to be load-balanced and scaled according to the incoming traffic and we need to ensure we service every request.
Design 3 – The Workers way
The final design we considered; Implementing the weighted traffic routing module in a Cloudflare Worker.
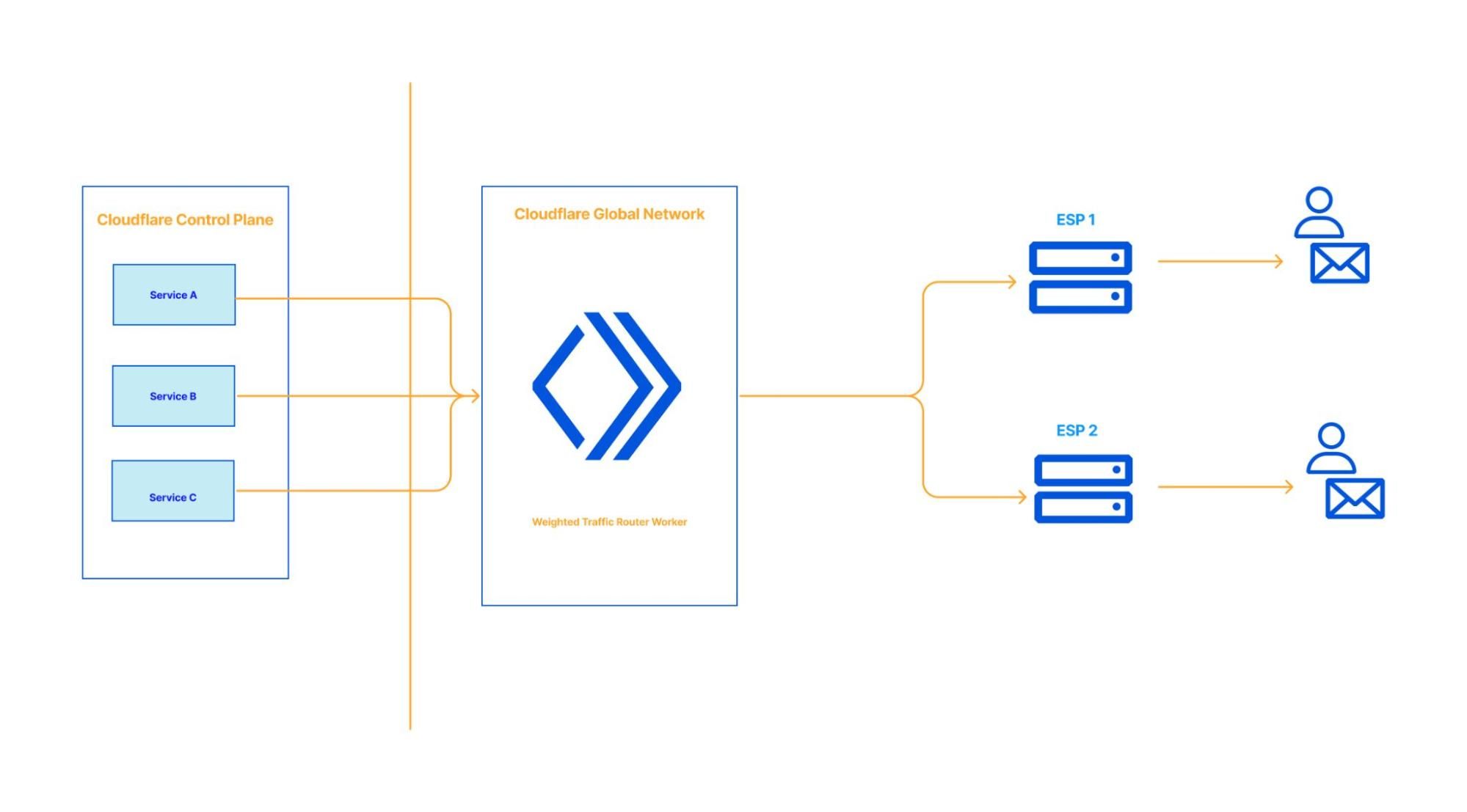
There are a lot of positives to doing it this way.
Firstly, minimal code changes are required in each service. In fact, nothing beyond the environment variables need to be updated. As with the previous design, when email vendor outages happen, only the Email Weighted Traffic Router Worker configuration has to be changed. One positive of using a Cloudflare Worker is when an environment variable is changed and deployed, it’s deployed in all of Cloudflare’s network in a few milliseconds. This is a significant advantage for us because it means the failover process takes only a few milliseconds; time-critical emails will reach our customers’ inbox on time, preventing major incidents.
Secondly, As the email traffic increases, we don’t have to care about scaling or load balancing the weighted-traffic-routing module. A Worker automatically takes care of it.
Finally, the operational overhead to building and running this is incredibly low. We don’t have to spend time on spinning up new containers, configuring and deploying them. The majority of the work is just to programme the algorithm that we discussed earlier.
There are still some drawbacks here though.We are still introducing a new service and an additional network hop. However, we can make use of the templates available here to make bootstrapping as efficient as possible.
Building it the Workers way
Weighing the pros and cons of the above approaches, we went with implementing it in a Cloudflare Worker.
The Email Traffic Router Worker sits in between the Cloudflare control plane and the ESPs and proxies requests between them. We stream raw responses from the upstream; the internal service is completely agnostic of multiple ESPs, and how the traffic is routed.
We configure the percentage of traffic we want to send to each vendor using environment variables. Cloudflare Workers provide environment variables which is a convenient way to configure a worker application.
addEventListener('fetch', async (event: FetchEvent)=> { try { const finalInstance=ratioBasedRandPicker( parseFloat(VENDOR1_TO_VENDOR2_RATIO), API_ENDPOINT_VENDOR1, API_ENDPOINT_VENDOR2, ) // stream request and response return doRequest(request, finalInstance) } catch (err) { // handle errors } }) export const ratioBasedRandPicker=( ratio: number, VENDOR1: string, VENDOR2: string, generator: ()=> number=Math.random, ): string=> { if (isNaN(ratio) || ratio <0 || ratio> 1) throw new ConfigurationError(`invalid ratio ${ratio}`) return generator() The Email Weighted Traffic Router Worker generates a random number between 0 (inclusive) and 1 with approximately uniform distribution over the range. When the ratio is set to 1, vendor 1 will be picked always, and similarly when it’s set to 0 vendor 2 will be picked all the time. For any values in between, the vendor is picked based on the weights assigned. Thus, when all the traffic has to be routed to vendor 1 we set the ratio to 1; the random numbers generated are always less than 1, hence vendor 1 will always be selected.
Doing a failover is as simple as updating the vendor1_to_vendor2 environment variable. In general, an environment variable for a Cloudflare Worker can be updated in one of the following ways:
Using Cloudflare Dashboard: All Worker environment variables are available to be configured in the Cloudflare Dashboard. Navigate to Workers -> Settings -> Variables -> Edit Variables and update the value
Using Wrangler (if your Worker is managed by wrangler): edit the environment variable in the wrangler.toml file and execute wrangler publish for the new values to kick in.
Once the variable is updated using one of the above methods, the Email Traffic Router Worker is deployed immediately in all Cloudflare data centers with this value. Hence all our emails will now be routed by the healthy vendor.
Now, we have built and shipped our weighted-traffic-routing logic in a Worker and building it in a Worker really accelerated our process of improving the resiliency.
The module is shipped, now what happens when the ESP is suffering an outage or a degraded performance? Let me conclude with a success story.
When an ESP outage happened
After deploying this Email Traffic Router Worker to production, we saw an outage declared by one of our vendors. We immediately configured our Traffic Router to send all traffic to the healthy vendor. Changing this configuration took about a few seconds, and deploying the change was even faster. Within a few milliseconds all the traffic was routed to the healthy instance, and all the critical emails reached their corresponding inboxes on time!
Looking at some timelines:
18:45 UTC – we get alerted that message delivery is slow/degraded from email provider 1. The other provider is not impacted
18:47 UTC – Teams within Cloudflare confirmed that their message outbound is experiencing delays
18:47 UTC – we decide to failover
18:50 UTC – we configured the Email Traffic Router Worker to dispatch all the traffic to the healthy email provider, deployed the changes
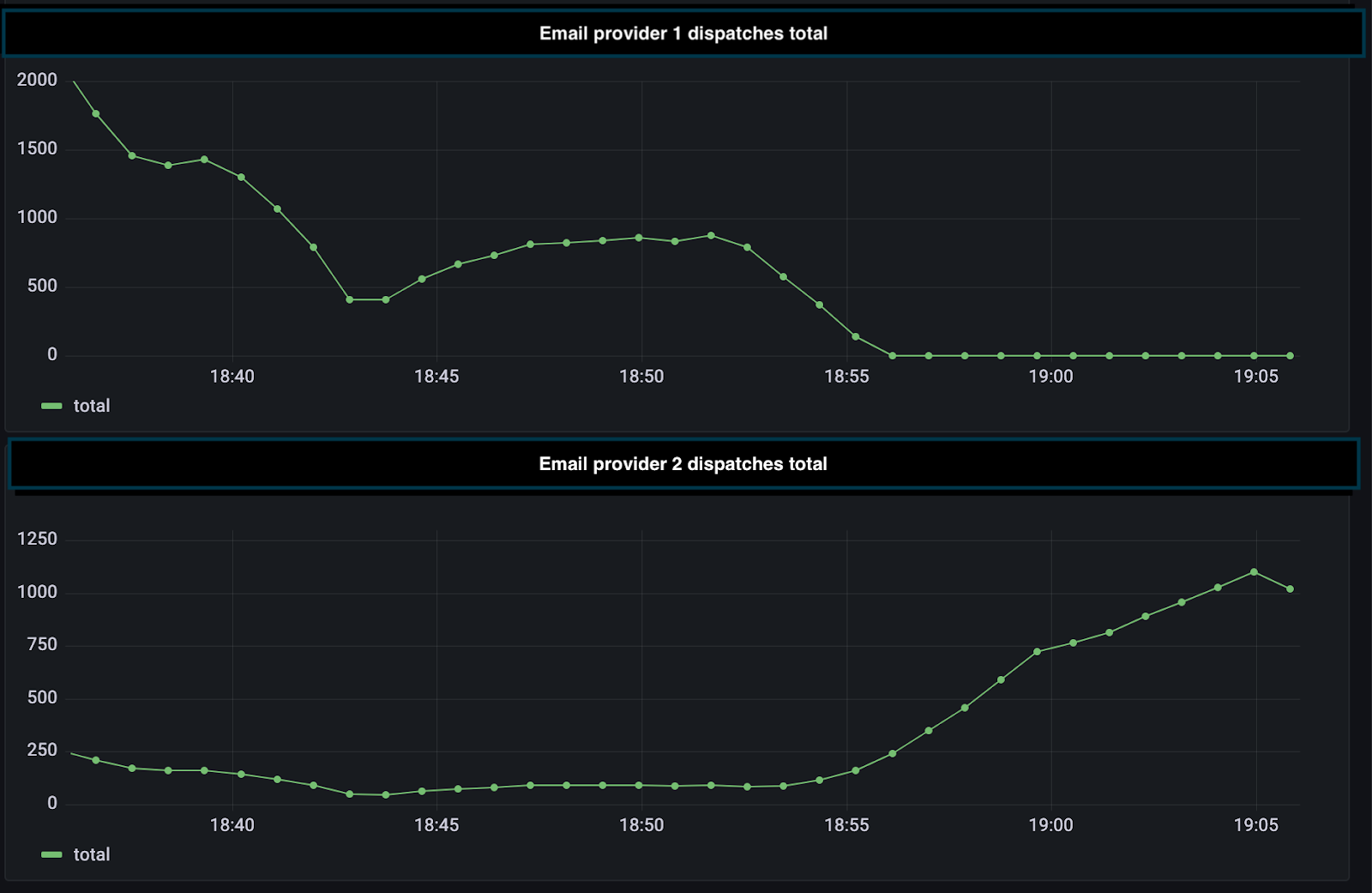
Starting 18:50 we saw a steady decrease in requests to email provider 1 and a steady uptick in the requests to the provider 2 instance.
Here’s our metrics dashboard:
Next steps
Currently, the failover step is manual. Our next step is to automate this process. Once we get notified that one of the vendors is experiencing outages, the Email Traffic Router Worker will failover automatically to the healthy vendor.
Conclusion
To reiterate our goals, we wanted to make our email notification systems resilient by
- adding another vendor
- having a simple and fast mechanism to failover when vendor outages happen
- achieving the above two objectives as quickly as possible to reduce customer impact
Thus our email systems are more reliable, and more resilient to any outages or failures of our email service providers. Cloudflare Worker makes it easy and simple to build and ship a production-ready service in no time; it also makes failovers possible without any code changes or downtime. It’s powerful that multiple services/teams within Cloudflare can rely on one place, the Email Traffic Router Worker, for uninterrupted email delivery.
Source: cloudflare.com




