
On 4 October 2023, Cloudflare experienced DNS resolution problems starting at 07:00 UTC and ending at 11:00 UTC. Some users of 1.1.1.1 or products like WARP, Zero Trust, or third party DNS resolvers which use 1.1.1.1 may have received SERVFAIL DNS responses to valid queries. We’re very sorry for this outage. This outage was an internal software error and not the result of an attack. In this blog, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
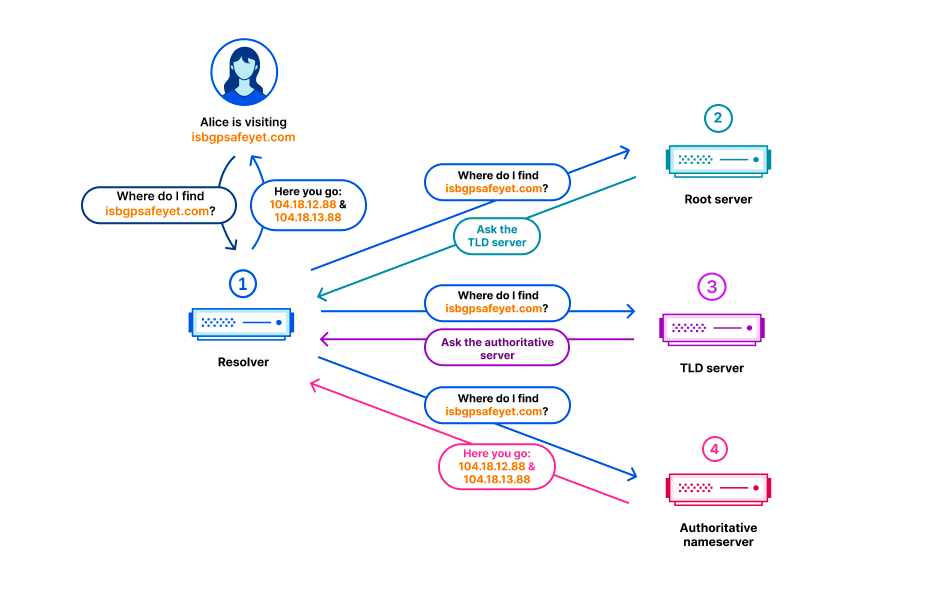
In the Domain Name System (DNS), every domain name exists within a DNS zone. The zone is a collection of domain names and host names that are controlled together. For example, Cloudflare is responsible for the domain name cloudflare.com, which we say is in the “cloudflare.com” zone. The .com top-level domain (TLD) is owned by a third party and is in the “com” zone. It gives directions on how to reach cloudflare.com. Above all of the TLDs is the root zone, which gives directions on how to reach TLDs. This means that the root zone is important in being able to resolve all other domain names. Like other important parts of the DNS, the root zone is signed with DNSSEC, which means the root zone itself contains cryptographic signatures.
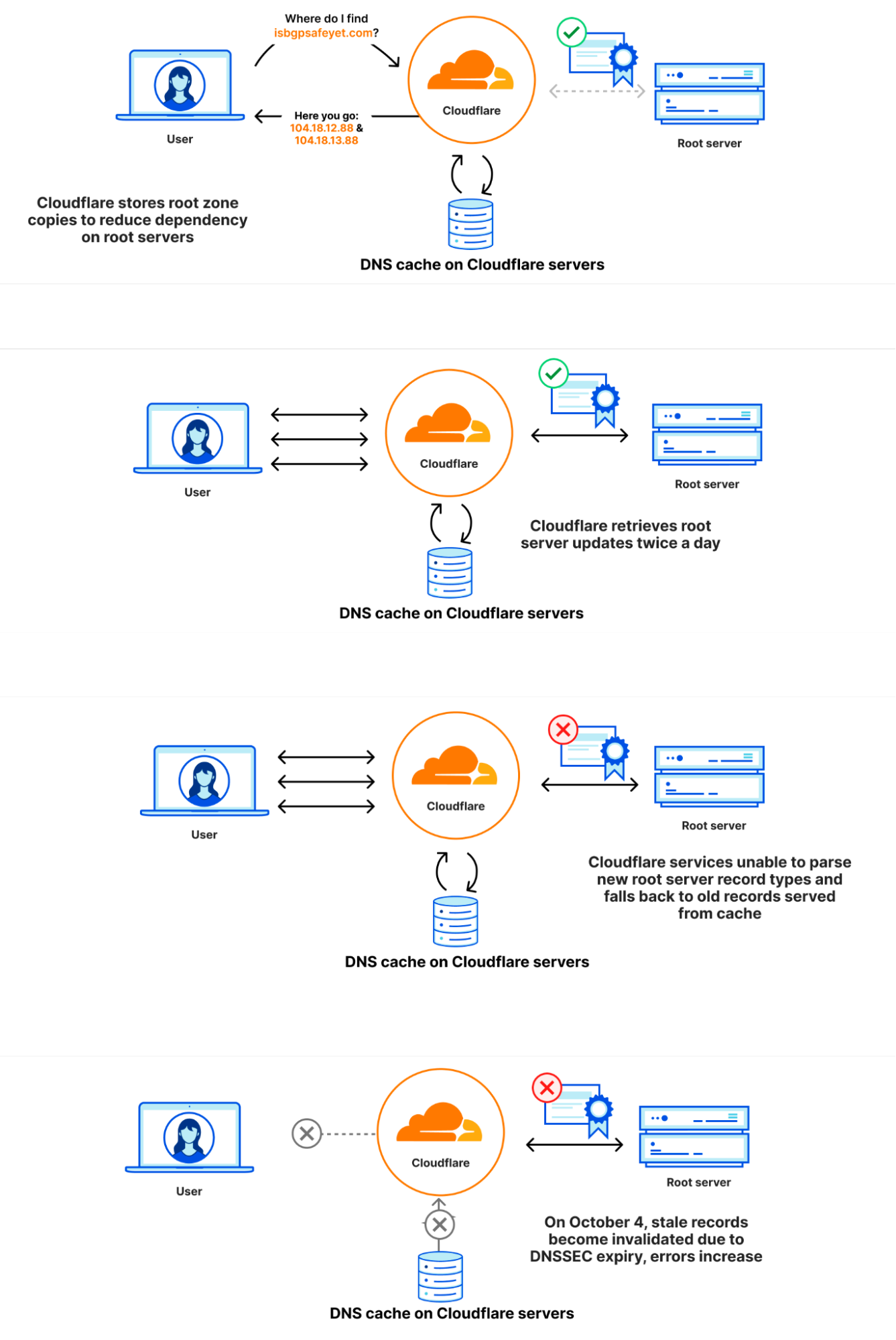
The root zone is published on the root servers, but it is also common for DNS operators to retrieve and retain a copy of the root zone automatically so that in the event that the root servers cannot be reached, the information in the root zone is still available. Cloudflare’s recursive DNS infrastructure takes this approach as it also makes the resolution process faster. New versions of the root zone are normally published twice a day. 1.1.1.1 has a WebAssembly app called static_zone running on top of the main DNS logic that serves those new versions when they are available.
What happened
On 21 September, as part of a known and planned change in root zone management, a new resource record type was included in the root zones for the first time. The new resource record is named ZONEMD, and is in effect a checksum for the contents of the root zone.
The root zone is retrieved by software running in Cloudflare’s core network. It is subsequently redistributed to Cloudflare’s data centers around the world. After the change, the root zone containing the ZONEMD record continued to be retrieved and distributed as normal. However, the 1.1.1.1 resolver systems that make use of that data had problems parsing the ZONEMD record. Because zones must be loaded and served in their entirety, the system’s failure to parse ZONEMD meant the new versions of the root zone were not used in Cloudflare’s resolver systems. Some of the servers hosting Cloudflare’s resolver infrastructure failed over to querying the DNS root servers directly on a request-by-request basis when they did not receive the new root zone. However, others continued to rely on the known working version of the root zone still available in their memory cache, which was the version pulled on 21 September before the change.
On 4 October 2023 at 07:00 UTC, the DNSSEC signatures in the version of the root zone from 21 September expired. Because there was no newer version that the Cloudflare resolver systems were able to use, some of Cloudflare’s resolver systems stopped being able to validate DNSSEC signatures and as a result started sending error responses (SERVFAIL). The rate at which Cloudflare resolvers generated SERVFAIL responses grew by 12%. The diagrams below illustrate the progression of the failure and how it became visible to users.
Incident timeline and impact
21 September 6:30 UTC: Last successful pull of the root zone.
4 October 7:00 UTC: DNSSEC signatures in the root zone obtained on 21 September expired causing an increase in SERVFAIL responses to client queries.
7:57: First external reports of unexpected SERVFAILs started coming in.
8:03: Internal Cloudflare incident declared.
8:50: Initial attempt made at stopping 1.1.1.1 from serving responses using the stale root zone file with an override rule.
10:30: Stopped 1.1.1.1 from preloading the root zone file entirely.
10:32: Responses returned to normal.
11:02: Incident closed.
This below chart shows the timeline of impact along with the percentage of DNS queries that returned with a SERVFAIL error:
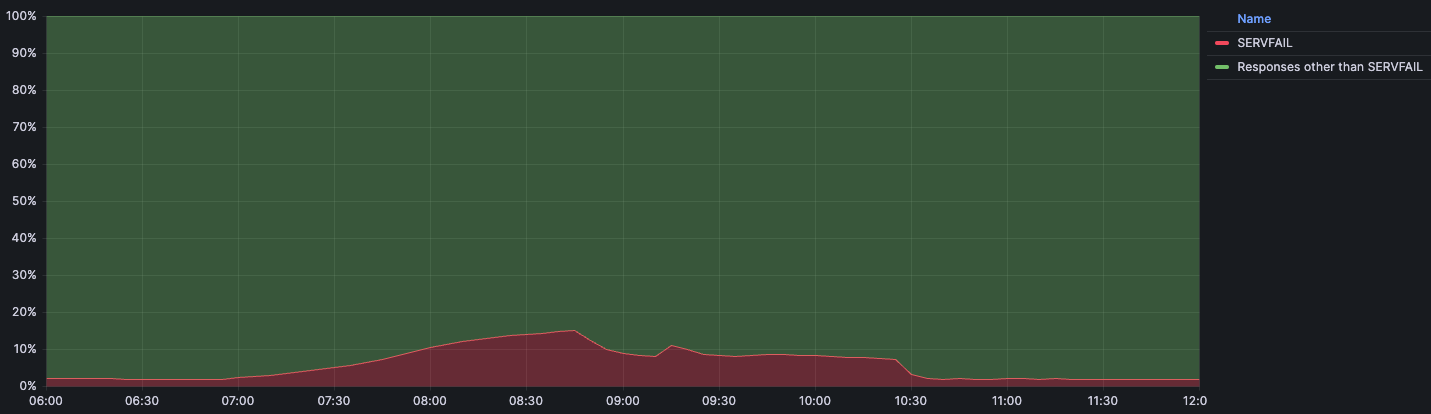
We expect a baseline volume of SERVFAIL errors for regular traffic during normal operation. Usually that percentage sits at around 3%. These SERVFAILs can be caused by legitimate issues in the DNSSEC chain, failures to connect to authoritative servers, authoritative servers taking too long to respond, and many others. During the incident the amount of SERVFAILs peaked at 15% of total queries, although the impact was not evenly distributed around the world and was mainly concentrated in our larger data centers like Ashburn, Virginia; Frankfurt, Germany; and Singapore.
Why this incident happened
Why parsing the ZONEMD record failed
DNS has a binary format for storing resource records. In this binary format the type of the resource record (TYPE) is stored as a 16-bit integer. The type of resource record determines how the resource data (RDATA) is parsed. When the record type is 1, this means it is an A record, and the RDATA can be parsed as an IPv4 address. Record type 28 is an AAAA record, whose RDATA can be parsed as an IPv6 address instead. When a parser runs into an unknown resource type it won’t know how to parse its RDATA, but fortunately it doesn’t have to: the RDLENGTH field indicates how long the RDATA field is, allowing the parser to treat it as an opaque data element.
1 1 1 1 1 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | | / / / NAME / | | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | TYPE | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | CLASS | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | TTL | | | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | RDLENGTH | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--| / RDATA / / / +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ The reason static_zone didn’t support the new ZONEMD record is because up until now we had chosen to distribute the root zone internally in its presentation format, rather than in the binary format. When looking at the text representation for a few resource records we can see there is a lot more variation in how different records are presented.
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2023100400 1800 900 604800 86400 . 86400 IN RRSIG SOA 8 0 86400 20231017050000 20231004040000 46780 . J5lVTygIkJHDBt6HHm1QLx7S0EItynbBijgNlcKs/W8FIkPBfCQmw5BsUTZAPVxKj7r2iNLRddwRcM/1sL49jV9Jtctn8OLLc9wtouBmg3LH94M0utW86dKSGEKtzGzWbi5hjVBlkroB8XVQxBphAUqGxNDxdE6AIAvh/eSSb3uSQrarxLnKWvHIHm5PORIOftkIRZ2kcA7Qtou9NqPCSE8fOM5EdXxussKChGthmN5AR5S2EruXIGGRd1vvEYBrRPv55BAWKKRERkaXhgAp7VikYzXesiRLdqVlTQd+fwy2tm/MTw+v3Un48wXPg1lRPlQXmQsuBwqg74Ts5r8w8w==. 518400 IN NS a.root-servers.net. . 86400 IN ZONEMD 2023100400 1 241 E375B158DAEE6141E1F784FDB66620CC4412EDE47C8892B975C90C6A102E97443678CCA4115E27195B468E33ABD9F78C Example records taken from https://www.internic.net/domain/root.zone
When we run into an unknown resource record it’s not always easy to know how to handle it. Because of this, the library we use to parse the root zone at the edge does not make an attempt at doing so, and instead returns a parser error.
Why a stale version of the root zone was used
The static_zone app, tasked with loading and parsing the root zone for the purpose of serving the root zone locally ( RFC 7706), stores the latest version in memory. When a new version is published it parses it and, when successfully done so, drops the old version. However, as parsing failed the static_zone app never switched to a newer version, and instead continued using the old version indefinitely. When the 1.1.1.1 service is first started the static_zone app does not have an existing version in memory. When it tries to parse the root zone it fails in doing so, but because it does not have an older version of the root zone to fall back on, it falls back on querying the root servers directly for incoming requests.
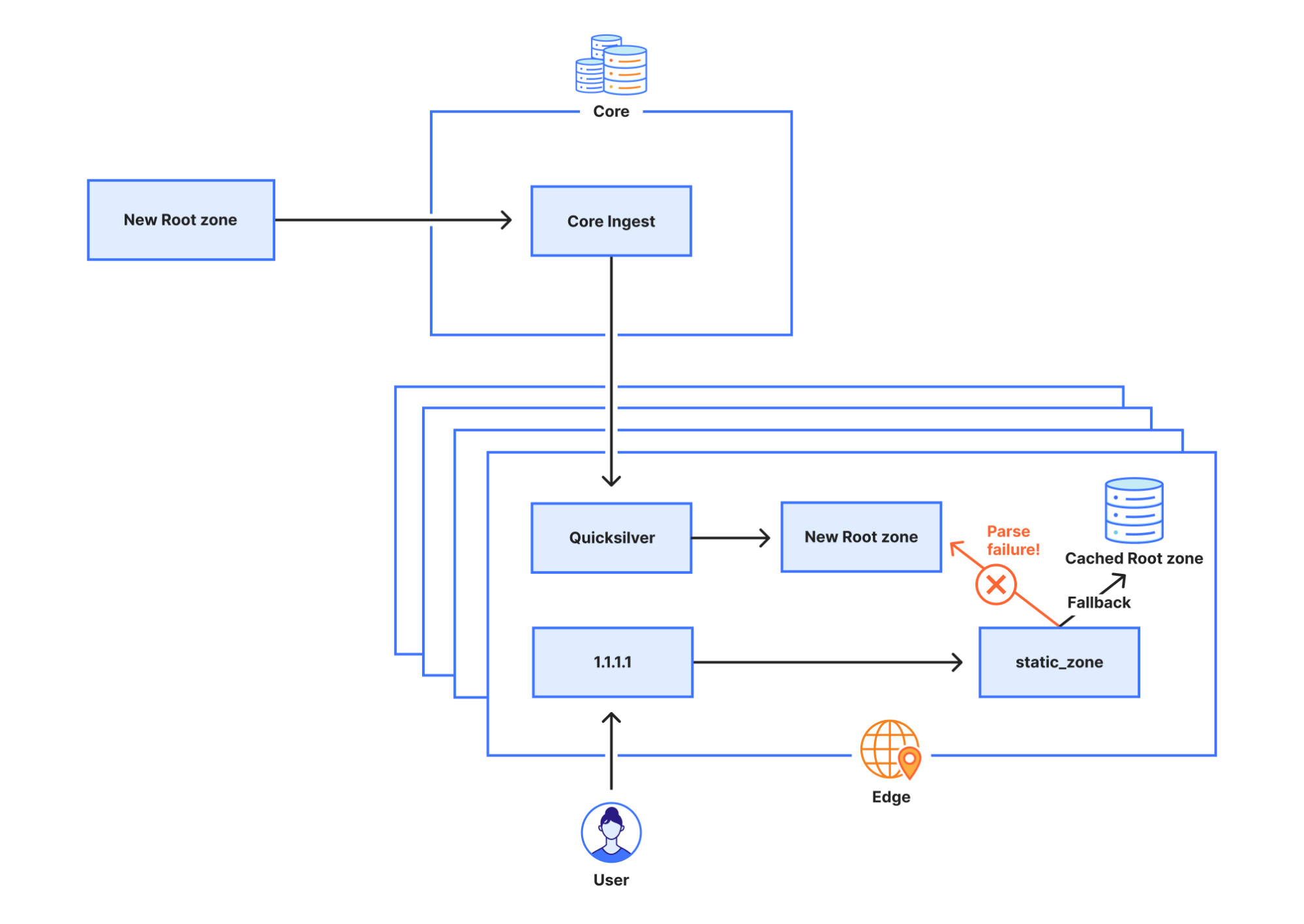
Why the initial attempt at disabling static_zone didn’t work
Initially we tried to disable the static_zone app through override rules, a mechanism that allows us to programmatically change some behavior of 1.1.1.1. The rule we deployed was:
phase=pre-cache set-tag rec_disable_static For any incoming request this rule adds the tag rec_disable_static to the request. Inside the static_zone app we check for this tag and, if it’s set, we do not return a response from the cached, static root zone. However, to improve cache performance queries are sometimes forwarded to another node if the current node can’t find the response in its own cache. Unfortunately, the rec_disable_static tag is not included in the queries being forwarded to other nodes, which caused the static_zone app to continue replying with stale information until we eventually disabled the app entirely.
Why the impact was partial
Cloudflare regularly performs rolling reboots of the servers that host our services for tasks like kernel updates that can only take effect after a full system restart. At the time of this outage, resolver server instances that were restarted between the ZONEMD change and the DNSSEC invalidation did not contribute to impact. If they had restarted during this two-week period, they would have failed to load the root zone on startup and fallen back to resolving by sending DNS queries to root servers instead. In addition, the resolver uses a technique called serve stale ( RFC 8767) with the purpose of being able to continue to serve popular records from a potentially stale cache to limit the impact. A record is considered to be stale once the TTL amount of seconds has passed since the record was retrieved from upstream. This prevented a total outage; impact was mainly felt in our largest data centers which had many servers that had not restarted the 1.1.1.1 service in that timeframe.
Remediation and follow-up steps
This incident had widespread impact, and we take the availability of our services very seriously. We have identified several areas of improvement and will continue to work on uncovering any other gaps that could cause a recurrence.
Here is what we are working on immediately:
Visibility: We’re adding alerts to notify when static_zone serves a stale root zone file. It should not have been the case that serving a stale root zone file went unnoticed for as long as it did. If we had been monitoring this better, with the caching that exists, there would have been no impact. It is our goal to protect our customers and their users from upstream changes.
Resilience: We will re-evaluate how we ingest and distribute the root zone internally. Our ingestion and distribution pipelines should handle new RRTYPEs seamlessly, and any brief interruption to the pipeline should be invisible to end users.
Testing: Despite having tests in place around this problem, including tests related to unreleased changes in parsing the new ZONEMD records, we did not adequately test what happens when the root zone fails to parse. We will improve our test coverage and the related processes.
Architecture: We should not use stale copies of the root zone past a certain point. While it’s certainly possible to continue to use stale root zone data for a limited amount of time, past a certain point there are unacceptable operational risks. We will take measures to ensure that the lifetime of cached root zone data is better managed as described in RFC 8806: Running a Root Server Local to a Resolver.
Conclusion
We are deeply sorry that this incident happened. There is one clear message from this incident: do not ever assume that something is not going to change! Many modern systems are built with a long chain of libraries that are pulled into the final executable, each one of those may have bugs or may not be updated early enough for programs to operate correctly when changes in input happen. We understand how important it is to have good testing in place that allows detection of regressions and systems and components that fail gracefully on changes to input. We understand that we need to always assume that “format” changes in the most critical systems of the internet (DNS and BGP) are going to have an impact.
We have a lot to follow up on internally and are working around the clock to make sure something like this does not happen again.
Source: cloudflare.com



