
Multiple Cloudflare services were unavailable for 37 minutes on October 30, 2023. This was due to the misconfiguration of a deployment tool used by Workers KV. This was a frustrating incident, made more difficult by Cloudflare’s reliance on our own suite of products. We are deeply sorry for the impact it had on customers. What follows is a discussion of what went wrong, how the incident was resolved, and the work we are undertaking to ensure it does not happen again.
Workers KV is our globally distributed key-value store. It is used by both customers and Cloudflare teams alike to manage configuration data, routing lookups, static asset bundles, authentication tokens, and other data that needs low-latency access.
During this incident, KV returned what it believed was a valid HTTP 401 (Unauthorized) status code instead of the requested key-value pair(s) due to a bug in a new deployment tool used by KV.
These errors manifested differently for each product depending on how KV is used by each service, with their impact detailed below.
What was impacted
A number of Cloudflare services depend on Workers KV for distributing configuration, routing information, static asset serving, and authentication state globally. These services instead received an HTTP 401 (Unauthorized) error when performing any get, put, delete, or list operation against a KV namespace.
Customers using the following Cloudflare products would have observed heightened error rates and/or would have been unable to access some or all features for the duration of the incident:
| Workers KV | Customers with applications leveraging KV saw those applications fail during the duration of this incident, including both the KV API within Workers, and the REST API. Workers applications not using KV were not impacted. |
| Pages | Applications hosted on Pages were unreachable for the duration of the incident and returned HTTP 500 errors to users. New Pages deployments also returned HTTP 500 errors to users for the duration. |
| Access | Users who were unauthenticated could not log in; any origin attempting to validate the JWT using the /certs endpoint would fail; any application with a device posture policy failed for all users. Existing logged-in sessions that did not use the /certs endpoint or posture checks were unaffected. Overall, a large percentage of existing sessions were still affected. |
| WARP / Zero Trust | Users were unable to register new devices or connect to resources subject to policies that enforce Device Posture checks or WARP Session timeouts. Devices already enrolled, resources not relying on device posture, or that had re-authorized outside of this window were unaffected. |
| Images | The Images API returned errors during the incident. Existing image delivery was not impacted. |
| Cache Purge (single file) | Single file purge was partially unavailable for the duration of the incident as some data centers could not access configuration data in KV. Data centers that had existing configuration data locally cached were unaffected. Other cache purge mechanisms, including purge by tag, were unaffected. |
| Workers | Uploading or editing Workers through the dashboard, wrangler or API returned errors during the incident. Deployed Workers were not impacted, unless they used KV. |
| AI Gateway | AI Gateway was not able to proxy requests for the duration of the incident. |
| Waiting Room | Waiting Room configuration is stored at the edge in Workers KV. Waiting Room configurations, and configuration changes, were unavailable and the service failed open. When access to KV was restored, some Waiting Room users would have experienced queuing as the service came back up. |
| Turnstile and Challenge Pages | Turnstile’s JavaScript assets are stored in KV, and the entry point for Turnstile (api.js) was not able to be served. Clients accessing pages using Turnstile could not initialize the Turnstile widget and would have failed closed during the incident window. Challenge Pages (which products like Custom, Managed and Rate Limiting rules use) also use Turnstile infrastructure for presenting challenge pages to users under specific conditions, and would have blocked users who were presented with a challenge during that period. |
| Cloudflare Dashboard | Parts of the Cloudflare dashboard that rely on Turnstile and/or our internal feature flag tooling (which uses KV for configuration) returned errors to users for the duration. |
Timeline
All timestamps referenced are in Coordinated Universal Time (UTC).
| 2023-10-30 18:58 UTC | The Workers KV team began a progressive deployment of a new KV build to production. |
| 2023-10-30 19:29 UTC | The internal progressive deployment API returns staging build GUID to a call to list production builds. |
| 2023-10-30 19:40 UTC | The progressive deployment API was used to continue rolling out the release. This routed a percentage of traffic to the wrong destination, triggering alerting and leading to the decision to roll back. |
| 2023-10-30 19:54 UTC | Rollback via progressive deployment API attempted, traffic starts to fail at scale. — IMPACT START — |
| 2023-10-30 20:15 UTC | Cloudflare engineers manually edit (via break glass mechanisms) deployment routes to revert to last known good build for the majority of traffic. |
| 2023-10-30 20:29 UTC | Workers KV error rates return to normal pre-incident levels, and impacted services recover within the following minute. |
| 2023-10-30 20:31 UTC | Impact resolved — IMPACT END — |
As shown in the above timeline, there was a delay between the time we realized we were having an issue at 19:54 UTC and the time we were actually able to perform the rollback at 20:15 UTC.
This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access leverages Workers KV as part of its request verification process. Due to this, we were unable to leverage our internal tooling and had to use break-glass mechanisms to bypass the normal tooling. As described below, we had not spent sufficient time testing the rollback mechanisms. We plan to harden this moving forward.
Resolution
Cloudflare engineers manually switched (via break glass mechanism) the production route to the previous working version of Workers KV, which immediately eliminated the failing request path and subsequently resolved the issue with the Workers KV deployment.
Analysis
Workers KV is a low-latency key-value store that allows users to store persistent data on Cloudflare’s network, as close to the users as possible. This distributed key-value store is used in many applications, some of which are first-party Cloudflare products like Pages, Access, and Zero Trust.
The Workers KV team was progressively deploying a new release using a specialized deployment tool. The deployment mechanism contains a staging and a production environment, and utilizes a process where the production environment is upgraded to the new version at progressive percentages until all production environments are upgraded to the most recent production build. The deployment tool had a latent bug with how it returns releases and their respective versions. Instead of returning releases from a single environment, the tool returned a broader list of releases than intended, resulting in production and staging releases being returned together.
In this incident, the service was deployed and tested in staging. But because of the deployment automation bug, when promoting to production, a script that had been deployed to the staging account was incorrectly referenced instead of the pre-production version on the production account. As a result, the deployment mechanism pointed the production environment to a version that was not running anywhere in the production environment, effectively black-holing traffic.
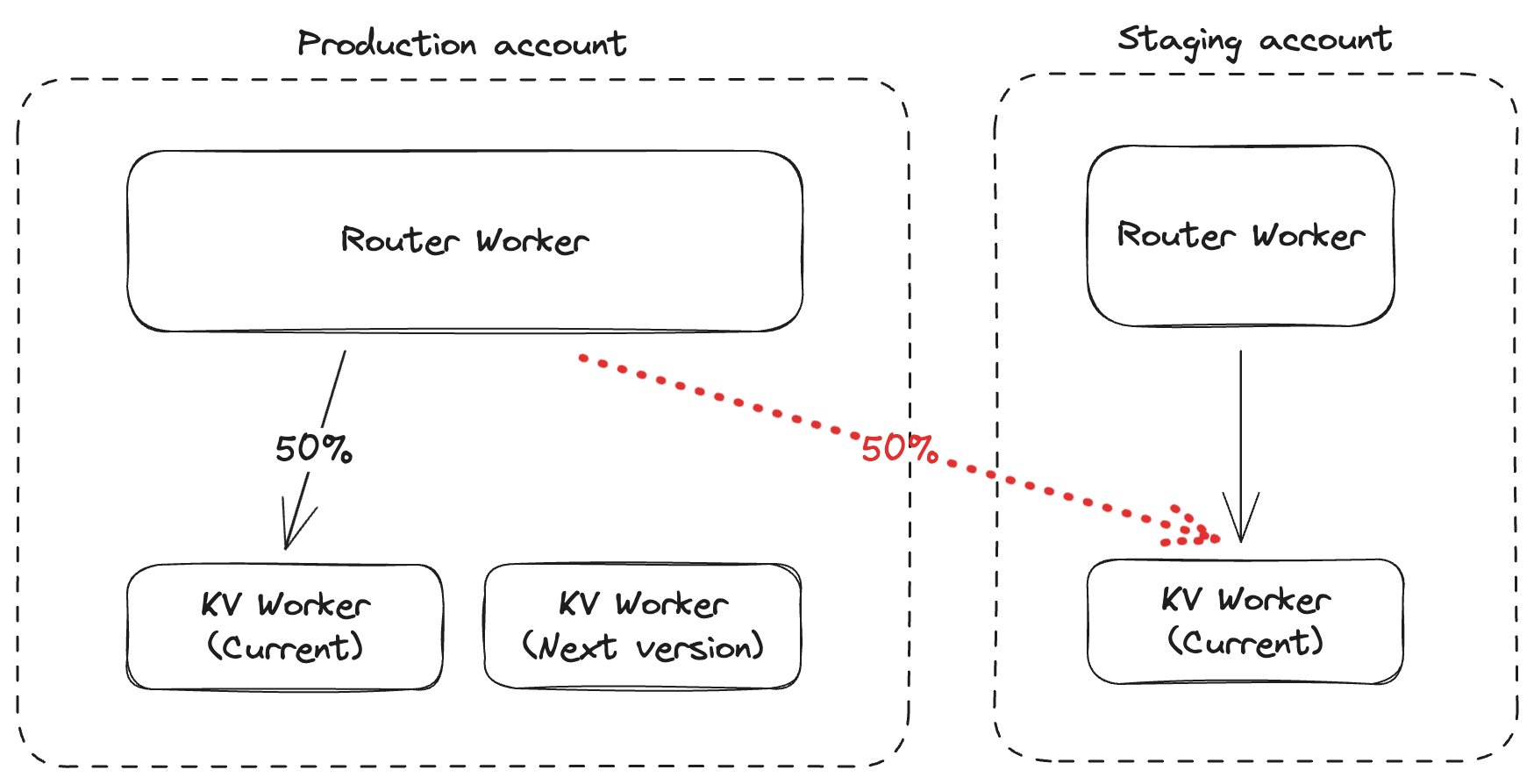
When this happened, Workers KV became unreachable in production, as calls to the product were directed to a version that was not authorized for production access, returning a HTTP 401 error code. This caused dependent products which stored key-value pairs in KV to fail, regardless of whether the key-value pair was cached locally or not.
Although automated alerting detected the issue immediately, there was a delay between the time we realized we were having an issue and the time we were actually able to perform the roll back. This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access uses Workers KV as part of the verification process for user JWTs (JSON Web Tokens).
These tools include the dashboard which was used to revert the change, and the authentication mechanism to access our continuous integration (CI) system. As Workers KV was down, so too were these services. Automatic rollbacks via our CI system had been successfully tested previously, but the authentication issues (Access relies on KV) due to the incident made accessing the necessary secrets to roll back the deploy impossible.
The fix ultimately was a manual change of the production build path to a previous and known good state. This path was known to have been deployed and was the previous production build before the attempted deployment.
Next steps
As more teams at Cloudflare have built on Workers, we have “organically” ended up in a place where Workers KV now underpins a tremendous amount of our products and services. This incident has continued to reinforce the need for us to revisit how we can reduce the blast radius of critical dependencies, which includes improving the sophistication of our deployment tooling, its ease-of-use for our internal teams, and product-level controls for these dependencies. We’re prioritizing these efforts to ensure that there is not a repeat of this incident.
This also reinforces the need for Cloudflare to improve the tooling, and the safety of said tooling, around progressive deployments of Workers applications internally and for customers.
This includes (but is not limited) to the below list of key follow-up actions (in no specific order) this quarter:
- Onboard KV deployments to standardized Workers deployment models which use automated systems for impact detection and recovery.
- Ensure that the rollback process has access to a known good deployment identifier and that it works when Cloudflare Access is down.
- Add pre-checks to deployments which will validate input parameters to ensure version mismatches don’t propagate to production environments.
- Harden the progressive deployment tooling to operate in a way that is designed for multi-tenancy. The current design assumes a single-tenant model.
- Add additional validation to progressive deployment scripts to verify that the deployment matches the app environment (production, staging, etc.).
Again, we’re extremely sorry this incident occurred, and take the impact of this incident on our customers extremely seriously.
Source: cloudflare.com



